
Organizations in most sectors today are rapidly adopting generative AI (GenAI). They are using it to improve productivity in manually intensive and document-heavy tasks and processes, as well as to create new product and service offerings and employee interactions. Along the way, they are discovering the untapped potential power of this still-emerging technology.
To harness that power and turn it into value, many CTOs have successfully applied BCG’s 10-20-70 Rule to their GenAI efforts: focus 10% of those efforts on the algorithms, 20% on the underlying technology and data, and 70% on people and processes. The technology and data component is critical for GenAI—and it is changing significantly as large language models (LLMs) evolve. Technological leaders need to shift their approach and adopt an enterprise AI foundation to navigate the complexities of successful GenAI scaling.
An organization’s enterprise AI foundation is a base that supports the GenAI activity of the entire organization, not just early adopters or a few product lines. It is structured to provide the digital and organizational infrastructure needed to sustain a GenAI-driven strategy. It supports all AI applications, complementary digital tools, and critical support capabilities such as AI literacy, talent, innovation, cybersecurity, and risk management. In addition, companies use the foundation to manage proprietary knowledge, unstructured data, and intellectual property. The value of a company’s IP, the success of its innovations, and its differentiation from competitors all link directly to the design of an enterprise foundation.
Some companies create an entirely new enterprise foundation when GenAI arrives. Others integrate GenAI into their existing IT system. Either way, the enterprise foundation is critical for Gen AI success—and yet it’s still relatively rare. One recent BCG study found that only 10% of global companies have brought one or more GenAI applications to scale, and lack of a tech foundation is a primary reason for this limited record of achievement.
Four emerging technological capabilities are key components of an enterprise GenAI foundation:
- Foundation Models. Companies use these LLMs, such as OpenAI’s GPT4 and Google’s Gemini, to create and maintain GenAI interactions, applications, and offerings. Some advanced organizations use them to create their own more custom language models, tailored to their customers and knowledge domains. After you decide on the approach you want to take, select and deploy the right foundation LLMs to align with your strategic priorities.
- GenAI Platforms. These underlying digital systems, deployed at scale, are unique to each company. They orchestrate, secure, monitor, manage, control, and provide access to LLMs around the company. Embrace a GenAI platform that integrates multiple foundation models and your own applications, thereby simplifying delivery of rich, varied experiences to your customers. Use prompt engineering and other adaptation and fine-tuning techniques to adapt the models to your specific needs.
- Data Layer. This is the accumulated body of information that machine learning models work with as they answer queries. The enterprise GenAI foundation includes your organization’s proprietary pools of information, which your applications can draw upon and which you can use to train your own custom models. The data may be structured or unstructured. You gather it from sources inside and outside the organization, and it becomes part of your value proposition. You can enhance your company’s data strategy by cultivating sources of future insight for GenAI use that are inaccessible to competitors.
- Operations and Monitoring. This core area involves testing and monitoring GenAI systems for performance, alignment with responsible AI practices, and overall impact. To stay at the forefront of new developments, including responsible AI, build organizational expertise in evaluating GenAI.
With these four priorities in place and with development of the enterprise AI foundation in progress, a company can create value with GenAI in three ways. It can deploy GenAI and predictive AI tools to handle everyday tasks and productivity gains. It can reshape HR, marketing, innovation, and other functional practices. And it can invent new internal and external offerings—its own custom GenAI models and other applications. As the company gains experience in all three ways of creating value, it develops and solidifies its scaled-up enterprise AI foundation.
The field of GenAI options and opportunities is continually growing and becoming more complex. In this article, we explain how to select, deploy, and adapt an enterprise AI foundation, use it for your own custom models, and stay ahead of the wave.
Selecting and Adapting Foundation Models
At its heart, GenAI is a data prediction software system that can generate realistic content in multiple forms: text, images, audio, video, and software. Foundation models are the underlying software engines on which GenAI depends.
A few major GenAI producers have dominated the foundation model market since OpenAI released ChatGPT in November 2022. Established innovators with continuously updated models include Google (Gemini), OpenAI and Microsoft (GPT), Anthropic (Claude), Meta (Llama), and Apple (Ferret). In the past two years, publicly available LLMs have proliferated as a constant stream of arrivals—each with its own lineage interrelated with the others—joins a host of relative newcomers. (See Exhibit 1.)
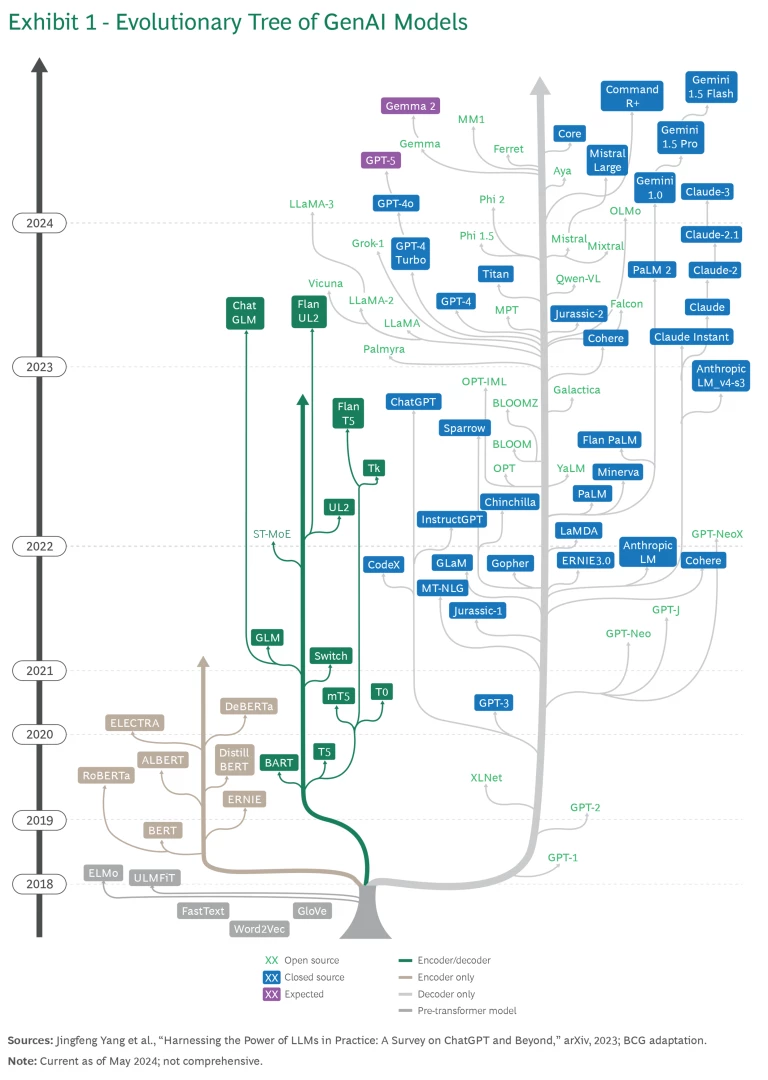
Despite their current diversity, these foundation models share a common research heritage in machine learning (ML) and the same broad customer base. The developers of these models—OpenAI, Google, Anthropic, Meta and Apple—train them with massive amounts of structured and unstructured data to identify patterns. The models can perform a wide range of tasks. Most compete on performance metrics such as speed, applicability, and accuracy. Available options range from open-source models that offer flexibility and cost-effectiveness to closed-source models that provide robust, highly optimized performance for specific tasks. (See Exhibit 2.)
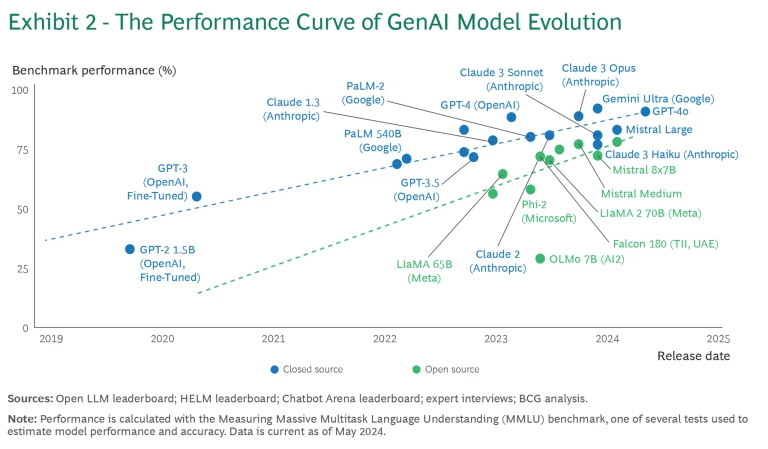
As a result, instead of having to rely on a single model such as GPT-4o to handle all GenAI tasks, your organization can deploy a different custom model for each use case. Although the additional layer of complexity increases the demand for talent and engineering resources, it also allows organizations to take advantage of each model’s exclusive features.
To select a foundation model, consider your purpose and weigh the tradeoff between cost and performance. The process is not as simple as picking one best model. The largest or most prominent model may not serve your needs. To navigate this terrain, first develop a strategic framework that reflects your organization’s values and priorities. Use a robust framework template like this one, tailoring it to your own requirements:
- Fitness for Purpose. What are the critical requirements for each custom model’s use case? How well does the foundation model align with them?
- Output. What formats—such as text, image, audio, video, code, or multimodal media—are needed? Can the model generate them?
- Size. How large a custom model does each use case require? Is hardware availability a limiting factor?
- Capabilities. What operations—such as math logic or general cognition—must the foundation model support? Does the model require training on large amounts of information?
- Performance. What are the demands for accuracy and speed? (For example, a chatbot must deliver rapid responses and relatively few hallucinations or missteps.)
- Flexibility. How much fine-tuning and adaptation will the custom model need? (Niche use cases, for example, may require adjustments.)
- Compatibility. Do the providers of your current IT systems, and the AI systems you might use in the future, support interoperability between custom and foundation models?
- Cost-Effectiveness. How is pricing for the foundation model structured, and is that arrangement optimal for the intended uses?
- Data Sensitivity. What ethical and regulatory implications do the use cases raise? (For example, are end users under age 21 involved? Is personal identifiable information included in the data? Are the foundation model and your custom model equipped to manage these and other issues responsibly?)
- Responsible AI and Regulations. How does the foundation model ensure compliance with principles of responsible AI and with regulatory requirements?
In many instances, after selecting a foundation model for a particular use case, you will want to tailor it further to your use case and thereby gain additional competitive advantage. There are many different adaptation techniques, with various pros, cons, and tradeoffs. You can layer and blend them to achieve optimal results.
Exhibit 3 shows two typical adaptation processes, each with a sequence of steps that build the company’s capacity for GenAI development. The left-hand side of the exhibit tracks a typical process in which the existing GenAI model remains essentially unchanged. Relevant use case examples include coding assistance apps for company staff, content generation apps that mimic a company’s brand and writing style, and customer service chatbots fine-tuned with a company’s specific product information and customer data.
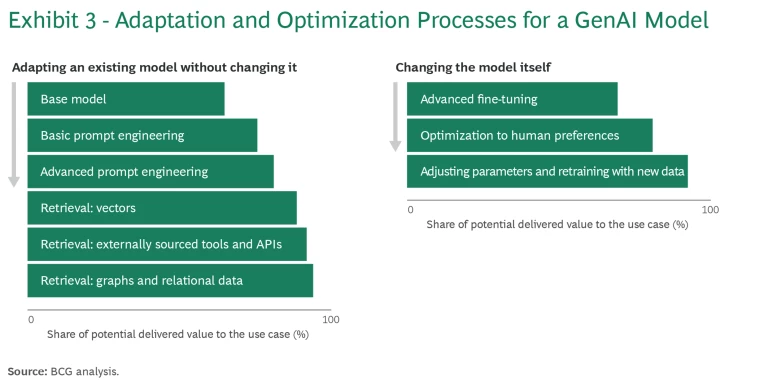
In these cases, adaptation starts with the base foundation model, as delivered by the vendor, and then refines it over a series of steps to bring it closer to a full-value offering. You create a minimum variable prototype (MVP) for your custom model or application. You release it to a subset of your user base, and test it in use, iterating and refining it until you have an offering acceptable for wide release. At each step, you introduce additional adaptation and optimization techniques to gain scale. You take stock to see whether it is can provide consistently cogent responses in your chosen area of interest. If its output is still too generic or its answers are incomplete, you move to the next technique.
The adaptation process illustrated in the exhibit begins with basic prompt engineering, which involves using techniques such as consistency sampling (generating multiple response options) and chain-of-thought sequences (breaking complex queries down into smaller steps). From there, it proceeds to more advanced prompt engineering, and then to techniques for retrieving and incorporating data from specified knowledge bases to expand the model’s existing range.
The process shown on the right-hand side of Exhibit 3 is suitable for use cases that require distinct LLM. Examples include industry-specific analyses for investment funds, health-care diagnostics models used by specialized medical institutions, and custom models for manufacturing optimization that integrate data from a company’s specific production processes, supply chain, and quality control systems.
Here, too, the process begins with creating an MVP to test and iterate, followed by fine-tuning it with techniques such as the exploration of reward attributes (XoRA), which masks or modifies different components of the model to observe how each change affects the model’s performance and output. The next step is preference optimization: training the MVP with user feedback and testing responses. The final step involves adjusting the model’s parameters—the settings that determine how the model processes data—and retraining it, perhaps from scratch, with data relevant to the particular use case.
You can augment either of these efforts with retrieval-augmented generation (RAG), which improves the accuracy of GenAI systems by having them query external databases. Ultimately, you may adopt even more advanced techniques, such as reinforcement learning from human feedback (RHLF), which trains models to use data from past human responses to improve their answer quality. The progression of techniques from XoRA to RAG to RLHF and beyond allows you to determine how much effort and investment to make in exchange for greater accuracy and higher-quality output. Your decisions—for example, about which methods to use and what algorithmic elements to adjust—depend on the particular use case and on the resources and talent available.
GenAI Platforms: Gateways to Creative Tools
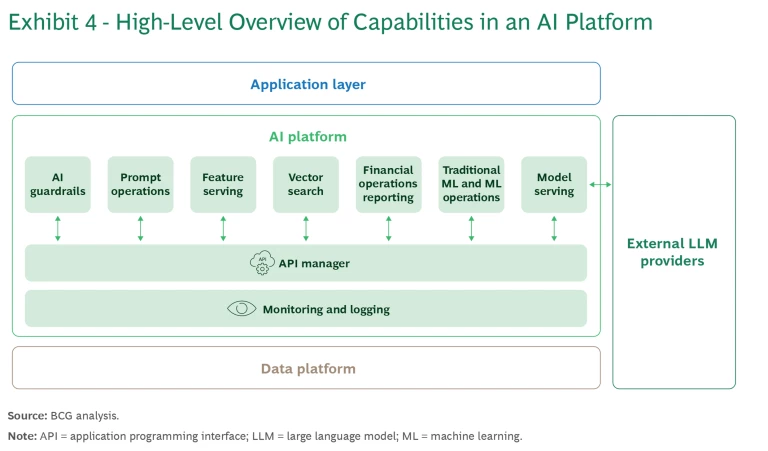
Platforms are the key to scaling up GenAI tools across the enterprise. Typically the enterprise AI foundation establishes and maintains these centralized hubs, which are also known as AI gateways. They offer access to the foundational and custom models, and to various GenAI system capabilities, including guardrails to safeguard accuracy and mitigate the effect of bias. They can also provide the necessary ML tools for seamlessly monitoring and maintaining in-house models and for integrating them with external models and other cloud-based services. Product-specific documentation, audit trails, and other oversight systems enable regulatory compliance and overall model governance on platforms.
Although it may seem that GenAI platforms represent an added expense, they actually reduce the time and resources needed to install and use GenAI. They provide easy access to a wide range of models and off-the-shelf tools for model customization. The platform appears to users as a gateway to a garden of models, with guardrails, maintenance tools, and data privacy support shared by all. (See Exhibit 4.)
The distinction between open- and closed-source foundation models is important. Closed-source models include such proprietary models as OpenAI’s GPT models, Google’s Gemini, and Anthropic’s Claude. Their providers strictly control access to the source code and other elements. Some closed-source models are oriented toward tech partnerships. For example, OpenAI has versions tailored to enterprise customers of its principal investor, Microsoft. It is difficult to modify most closed-source models directly, but they generally include detailed controls for privacy and security.
In contrast, open-source foundation models offer their users access to coding, development, and deployment features. The most prominent example, Meta’s LLama3, delivers performance that rivals that of the best proprietary models, shaking up the market. Other notable open-source text models are X.AI’s Grok-2, Mistral’s Medium, and the Technology Innovation Institute’s Falcon. Documentation for customizing open-source models may not be readily available, but you can usually rely on user communities or other IT resources for support.
Hybrid systems are emerging, too. Some closed-source providers are releasing open-source versions such as Microsoft’s Phi3 and WizardLM2. Conversely, some open-source providers offer closed-source adaptations, like Mistral Large on Azure.
Finally, as platforms take hold, more organizations will develop their own custom GenAI models trained on their proprietary data. Admittedly, the skills for doing this are in short supply today. Only about 1% of current GenAI-ready talent possess the ability to fine-tune LLMs effectively. As they develop or recruit people with these skills, however, companies can use open-source GenAI as a building block in developing the platform architecture they need to manage, access, and store data.
Data Layers: The Source of Competitive Advantage
Access to data is critical for establishing a company’s position in the GenAI era. The amount of data needed, its requisite quality, and the privacy and intellectual property concerns related to it depend on the use case and its context. Having proprietary data to leverage in GenAI systems can be a valuable source of competitive advantage. In many cases, higher-quality, domain-specific data is necessary, and such data can be difficult to curate, integrate, and validate. In other cases, relatively little data is needed to train the models, as long as that data accurately represents the user base. The rest of the data will subsequently emerge during system testing and use. For example, just a few historical customer interactions may be enough to train a GenAI call center model for launch. From there, the model will grow stronger as it learns from its customer interactions.
To develop systems with advanced levels of knowledge, organizations must draw from a diverse data pool. The relevant data sets are inherently multimodal: digital records of the human senses. The formats may include texts, code, structured databases, interactive transcripts, visuals, moving images, and audio—anything from speech to symphonies to sound effects. The array of data serves as the lifeblood of top GenAI models, giving them a multidimensional grasp of our world and enabling their immense capabilities. (See Exhibit 5.)
Challenges related to data gathering include privacy-related concerns and legal restrictions that add labor and expense to the process. Data ownership can be a complex puzzle, with insights sometimes locked in different departmental silos, each with its own rules and integration issues. Past communications may contain built-in biases, errors, inconsistencies, and inequities. Data may be outdated, incomplete, or inconsistently formatted. Fortunately, various methods are available to curate data, raise its quality, or train models effectively with limited data sets.
GenAI can help by creating synthetic data. This species of data consists of simulations of actual human-derived data that you can then use to train GenAI and predictive AI models. If the actual data set on hand does not cover the necessary range of detail, the algorithm can extrapolate synthetic data to fill the statistical gaps. For example, it can create avatars whose behavior mimics that of real people and whose responses can credibly contribute to the data pool.
You can also use GenAI to find sources of more data, unlock data that might otherwise be inaccessible, reconcile inconsistencies, and improve data management practices. The overall system can streamline data integration, merge information from diverse sources, and automate the anonymization of datasets to comply with privacy requirements.
In some cases, the data may be biased, perhaps because it reflects biased past communications. To ensure data quality, you may need to invest in human oversight, such as strategically placed “human-in-the-loop” practices. You may also need to invest in data governance. Clear policies and practices can help manage risks, ensure compliance with emerging regulations, preserve appropriate data ownership and security, and maintain data integrity, confidentiality, and availability. The ultimate goal of robust data governance is to foster trust in your AI systems through transparency and accountability. In a market dominated by automated interaction, trust becomes a source of competitive advantage.
Operations and Monitoring: Evaluate or Fail
The fourth and most elusive element of a GenAI enterprise foundation is operations and monitoring. Organizations need to take responsibility for how their GenAI systems and products perform, but most current evaluation processes are not yet equipped to handle this task. There is a general need for more robust evaluation capabilities, with a particular focus on responsible AI as a critical enabler of competitive advantage.
One key problem is that today’s prevailing approach to benchmarking GenAI performance assesses overall capabilities and knowledge but does not reliably indicate whether a model truly understands business processes and whether it can interact appropriately with customers. Many benchmark systems cherry-pick data that show positive performance. Some models may perform poorly in reality despite earning high scores on benchmarks. Differences in evaluation methodology make it hard to rely on metrics as indicators of a model’s quality and value.
The solution is to follow a GenAI operational standard that measures response quality, technical performance, responsible AI, and business impact. (See Exhibit 6.) The evolving prompt operations (PromptOps) tooling landscape offers a set of capabilities that unify relevant operational standards into a single toolkit to manage the PromptOps life cycle and systematically evaluate iterative changes. Examples include Langsmith, Langfuse, and Phoenix.

Response quality gauges how closely AI-generated responses align with user expectations, focusing on the content’s relevance and capacity to attract emotional engagement. Assessments of technical performance involve metrics such as response speed, handling capacity, and system uptime. Ethical standards reflect the tenets of responsible AI, such as fairness and accountability. Accountability is not simply a matter of compliance; it is a strategic way to stand out in a competitive market. Finally, improvements in ROI, customer satisfaction, and cost provide a basis for measuring overall business impact.
Conclusion: Taking Action
As a content-generating tool, GenAI is producing new ideas, personalizing experiences, and triggering remarkable changes in marketing, innovation, and customer service. Its use is also galvanizing predictive AI—the analytic uses of ML—to augment decision making, recommendations, and computation of future probabilities.
More than two-thirds of senior executives that BCG surveyed in December 2023 said GenAI will be the most disruptive innovation of the next five years—and one-third are already ramping up their digital investments in response. Their goal is to harness the power of GenAI and predictive AI together.
Your company is undoubtedly doing the same. The challenges related to people and process (the 70% in BCG’s 70-20-10 formula) and algorithmic design (the 10%) are probably top of mind for you. But don’t let the enterprise foundation for GenAI (the remaining 20%) fall by the wayside. It is a great source of leverage for meeting the challenges of GenAI and successfully integrating this vital technology into your organization.
The authors thank the BCG GenAI global leadership team: Vladimir Lukić, Nicolas de Bellefonds, Marc Schuuring, Benjamin Rehberg, Djon Kleine, and Steve Mills. We also thank BCG’s GenAI case team: Allison Bailey, Lane McBride, Sibley Nebergall, Brittany Bankston, Lydia Atangcho, Harry Ball, and Emma Conover-Crockett.